知识库
大语言模型的训练数据一般基于公开的数据,且每一次训练需要消耗大量算力,这意味着模型的知识一般不会包含私有领域的知识,同时在公开知识领域存在一定的滞后性。为了解决这一问题,目前通用的方案是采用 RAG(检索增强生成)技术,根据用户提出的问题来匹配最相关的外部数据,将检索到的相关内容召回后作为模型提示词的上下文来重新组织回复。
SenseFlow的知识库功能将 RAG 的各处理步骤可视化,提供了一套简单易用��的用户界面来方便应用构建者管理知识库,并能够快速集成至 AI 应用中。
支持的文件格式
SenseFlow支持以下格式的文档:
- 长文本内容:TXT、Markdown、PDF、HTML、DOCX、EPUB
- 结构化数据:XLSX、XLS、CSV、XML
- 演示文档:PPT、PPTX
- 邮件数据:EML、MSG
核心概念
在SenseFlow中,知识库(Knowledge)是一些文档(Documents)的集合,文档并不局限于某种特定的格式,它是一个泛指的概念,涵盖了所有上传到知识库的数据。作为文档集合的知识库可以被整体集成至一个应用中作为检索上下文使用。
创建知识库
创建知识库并上传文件大致分为以下步骤:
- 在 SenseFlow 工作台内点击创建知识库,填写知识库名称
- 选择所需要的 Embedding 模型
- 配置检索设置,确认创建
- 从本地选择你需要上传的文件,等待分段嵌入
- 选择分段与清洗模式,预览效果
- 保存并处理,在应用内关联并使用
1. 创建知识库与命名
在 SenseFlow 工作台的导航栏中点击知识库,点击"创建知识库" 进入创建向导,填写知识库名称。
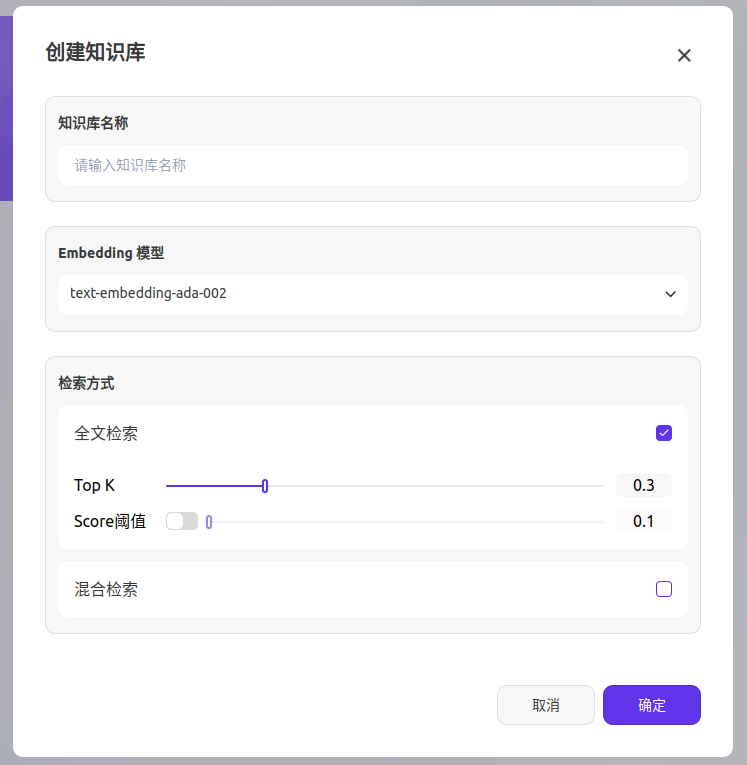
2. 选择 Embedding 模型
Embedding是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
Embedding模型是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。选择不同的Embedding模型会根据不同的任务需求和数据特点,找到最适合的模型来实现最优的文本表示。
3. 配置检索方式
SenseFlow 提供以下两种检索方案:
全文检索
定义:关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。

配置参数:
-
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。数值越高,预期被召回的文本分段数量越多。
-
Score 阈值:用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
混合检索
定义:同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定"权重设置"进行检索。
权重设置:允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
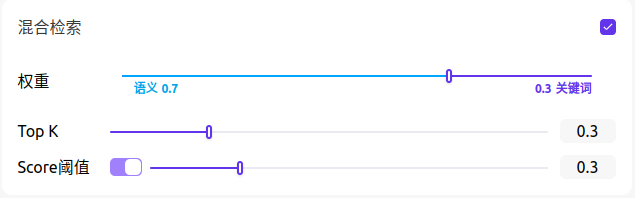
权重选项:
-
语义值为 1:仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
-
关键词值为 1:仅启用关键词检索模式。通过用户输入的信��息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
-
自定义权重:除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
4. 上传文件
拖拽或选中文件进行上传,单个文件的文件大小不能超过15MB。
如果还没有准备好文档,可以先创建一个空知识库。
5. 分段与清洗策略
将内容上传至知识库后,需要先对内容进行分段与数据清洗,该阶段可以被理解为是对内容预处理与结构化。
什么是分段与清洗?
分段:大语言模型存在有限的上下文窗口,无法将知识库中的所有内容发送至 LLM。因此可以将整段长文本分段处理,再基于用户问题,召回与关联度最高的段落内容,即采用分段 TopK 召回模式。此外,将用户问题与文本分段进行语义匹配时,合适的分段大小有助于找到知识库内关联性最高的文本内容,减少信息噪音。
清洗:为了保证文本召回的效��果,通常需要在将数据录入知识库之前便对其进行清理。例如,如果文本内容中存在无意义的字符或者空行,可能会影响问题回复的质量。
分段与清洗策略
自动分段与清洗:自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,SenseFlow 将为你自动分段与清洗内容文件。
自定义:自定义模式适合对于文本处理有明确需求的进阶用户。在自定义模式下,你可以根据不同的文档格式和场景要求,手动配置文本的分段规则和清洗策略。
自定义分段规则
-
分段标识符:指定标识符,系统将在文本中出现该标识符时分段。例如填写
\n(正则表达式中的换行符),文本换行时将自动分段 -
分段最大长度:根据分段的文本字符数最大上限来进行分段,超出该长度时将强制分段。一个分段的最大长度为 1000 Tokens
-
分段重叠长度:分段重叠指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%
文本预处理规则
文本预处理规则可以帮助过滤知识库内部分无意义的内容:
- 替换连续的空格、换行符和制表符
- 删除所有 URL 和电子邮件地址
6. 处理并完成
配置完上文所述的各项配置后,点击"保存并处理"即可完成知识库的创建。
知识库管理
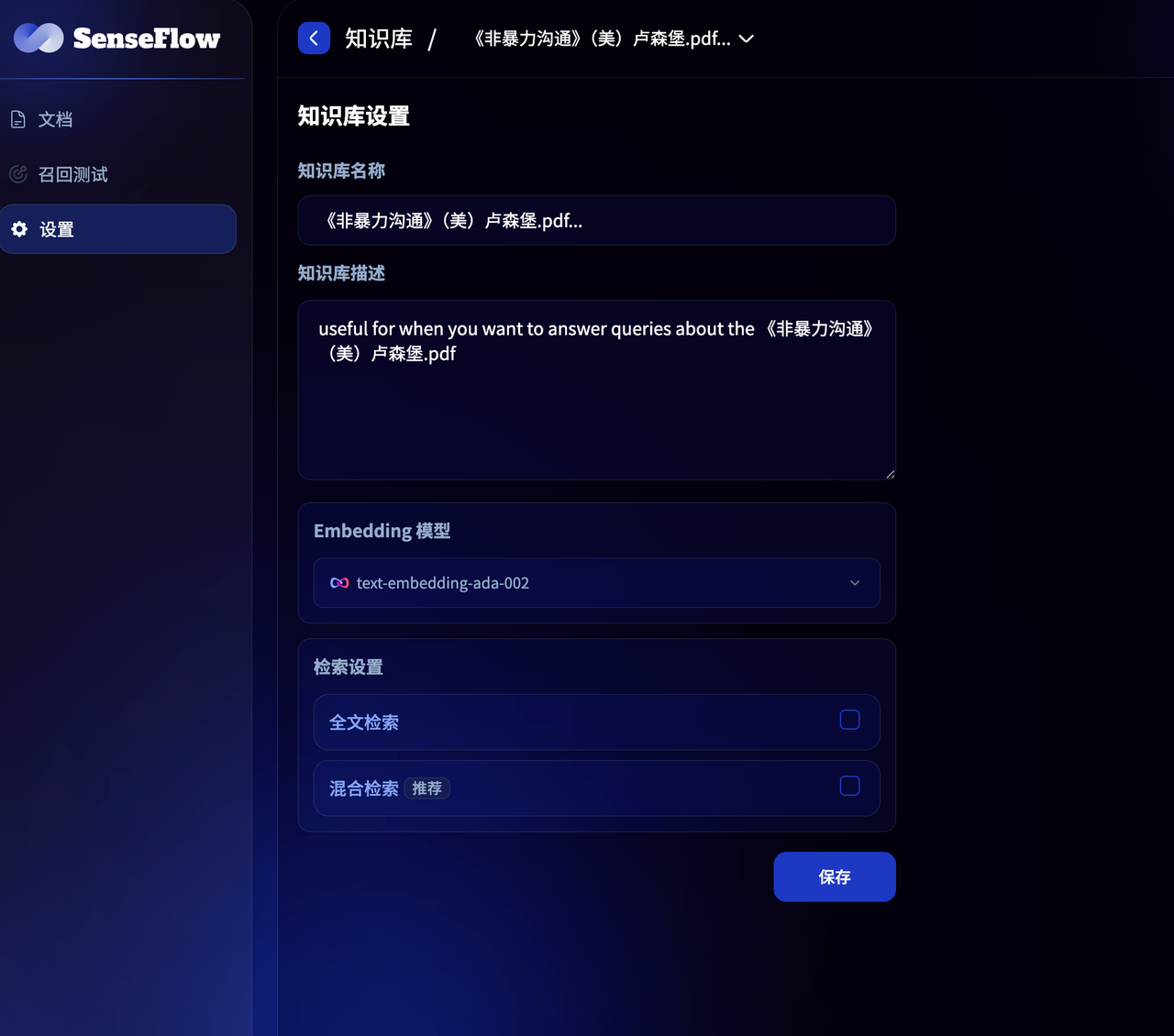
基本设置管理
在 SenseFlow 工作台中,点击顶部的 "知识库" tab 页,选择需要管理的知识库,轻点左侧导航中的设置进行调整。你可以调整:
- 知识库名称:用于区分不同的知识库
- 知识库描述:用于描述知识库内文档代表的信息
- Embedding 模型:修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除
- 检索设置:调整检索方式和参数
文档管理
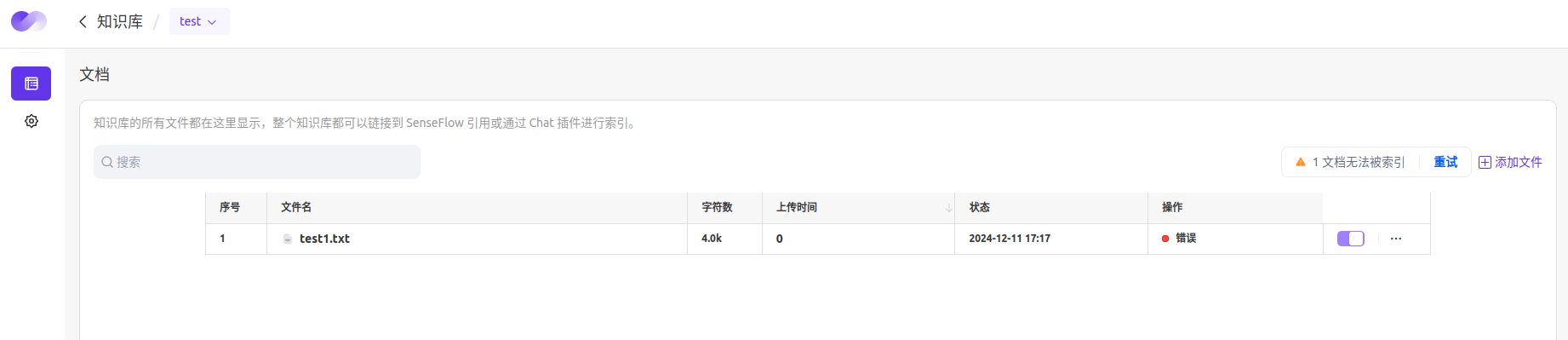
添加文档
点击 「知识库」 > 「文档列表」,然后轻点 「添加文件」,即可在已创建的知识库内上传新的文档。
文档状态管理
禁用文档:知识库支持将暂时不想被索引的文档或分段进行禁用,在知识库文档列表,点击禁用按钮,则文档被禁用;在文档详情中可以禁用某个分段,禁用的分段将不会被索引。禁用的文档点击启用,可以取消禁用。
归档文档:一些不再使用的旧文档数据,如果不想删除可以将它进行归档,归档后的数据就只能查看或删除,不可以进行编辑。在知识库文档列表,点击归档按钮,则文档被归档,也可以在文档详情,归档文档。归档的文档将不会被索引。归档的文档也可以点击撤销归档。
文档分段管理
查看文本分段
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
检查分段质量
文档分段对于知识库应用的问答效果有明显影响,在将知识库与应用关联之前,建议人工检查分段质量。
通过字符长度、标识符或者 NLP 语义分段等机器自动化的分段方式虽然能够显著减少大规模文本分段的工作量,但分段质量与不同文档格式的文本结构、前后文的语义联系都有关系,通过人工检查和订正可以有效弥补机器分段在语义识别方面的缺点。
检查分段质量时,一般需要关注以下几种情况:
- 过短的文本分段:导致语义缺失
- 过长的文本分段:导致语义噪音影响匹配准确性
- 明显的语义截断:在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容
编辑分段
添加文本分段:在分段列表内点击 「添加分段」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
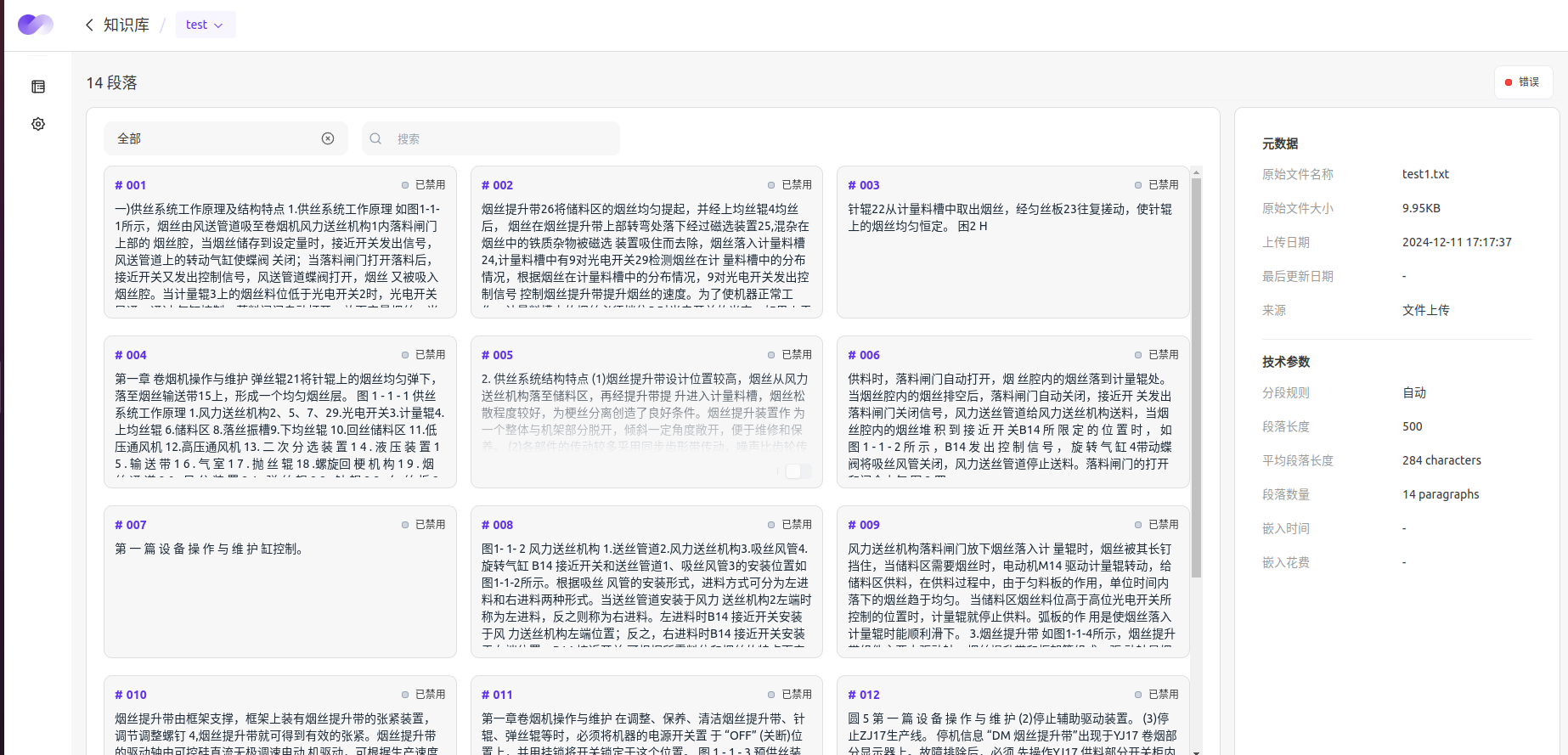
批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
编辑文本分段:在分段列表内,你可以对已添�加的分段内容直接进行编辑修改,包括分段的文本内容和关键词。
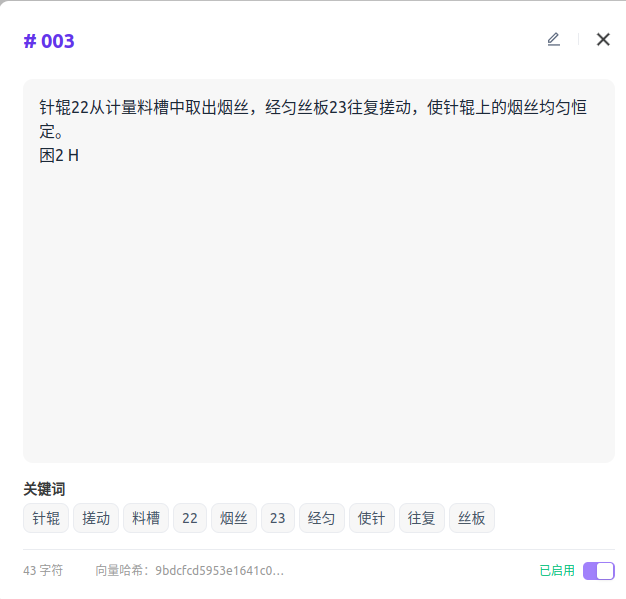
在应用中集成知识库
知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,你可以在 SenseFlow 的所有应用类型内关联已创建的知识库。
集成步骤
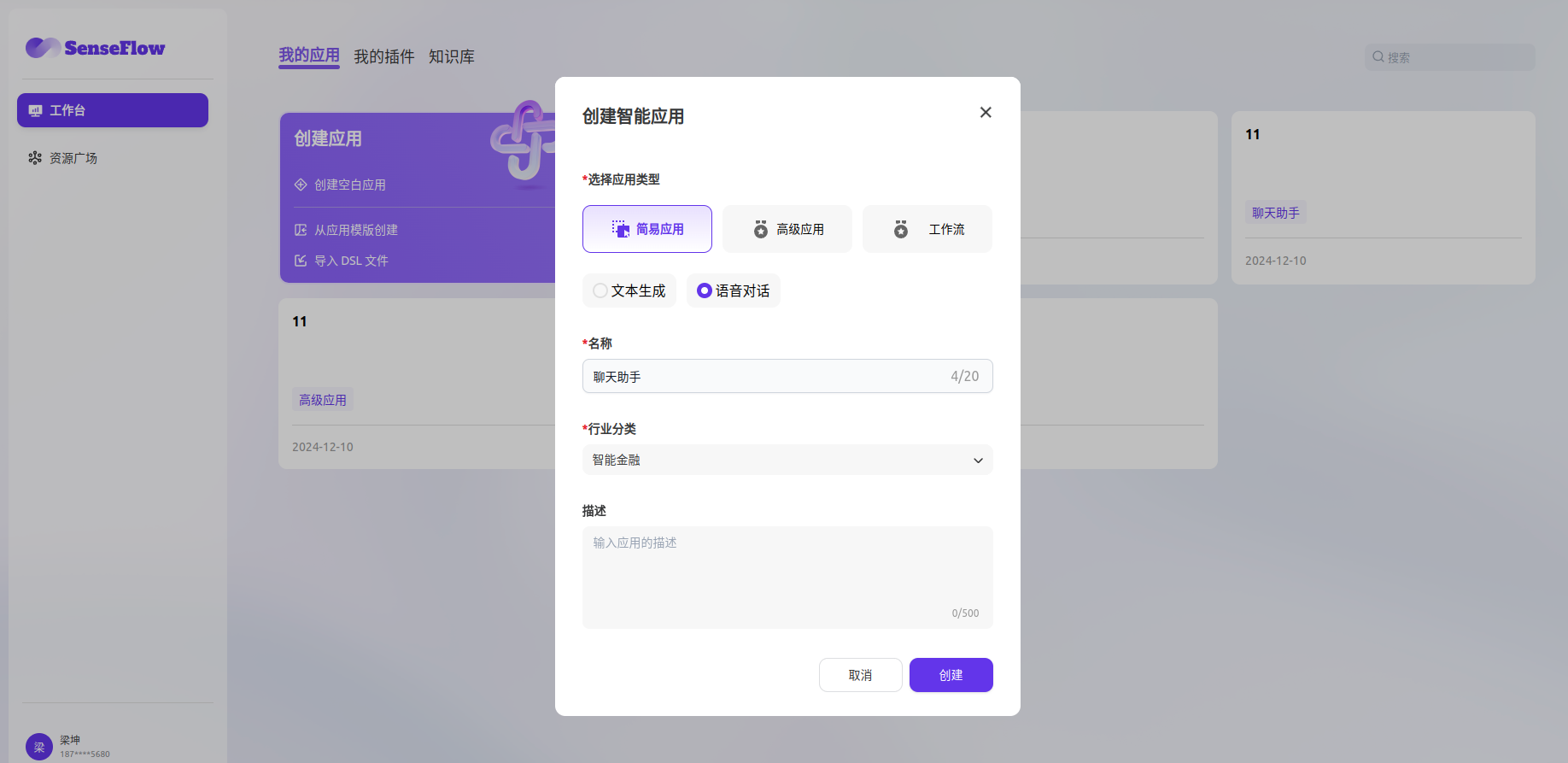
- 进入 我的应用 -- 创建应用 -- 智能体,点击创建
- 在 知识库 模块点击 添加 选择已创建的知识库
- 在 调试与预览 内输入与知识库相关的用户问题进行调试
- 调试完成之后保存并发布为一个 AI 知识库问答类应用,通过API接入
最佳实践
内容准备
- 内容质量:确保上传的文档内容准确、完整、��结构化
- 格式标准:使用标准的文档格式,便于系统解析
- 内容更新:定期更新过时信息,保持知识库的时效性
- 内容组织:合理组织文档结构,便于检索和管理
分段优化
- 合理分段长度:根据内容特点选择合适的分段长度
- 保持语义完整性:避免在重要语义点进行分段
- 设置适当重叠:通过分段重叠保持上下文连贯性
- 人工检查:对重要文档进行人工分段质量检查
检索配置
- 选择合适的检索方式:根据应用场景选择全文检索或混合检索
- 调优参数设置:通过测试找到最佳的TopK和Score阈值
- 权重调整:在混合检索模式下不断调整语义和关键词权重
- 定期评估:定期评估检索效果并进行调整
维护管理
- 定期清理:清理过时或无用的文档
- 版本管理:保持文档版本的更新和管理
- 权限控制:合理设置知识库的访问权限
- 性能监控:监控知识库的使用效果和性能表现
通过合理使用知识库功��能,您可以为智能应用提供强大的专业知识支持,显著提升应用的回答质量和用户体验。
下一步:了解插件功能