为智能应用设置语音与识别能力
语音配置概述
SenseFlow创新地支持了克隆音色、文生音色和音色融合,期待您创造出更加生动的音色。
为应用配置个性化语音功能可以显著提升用户体验,实现更自然的人机交互。以下是主要配置步骤:
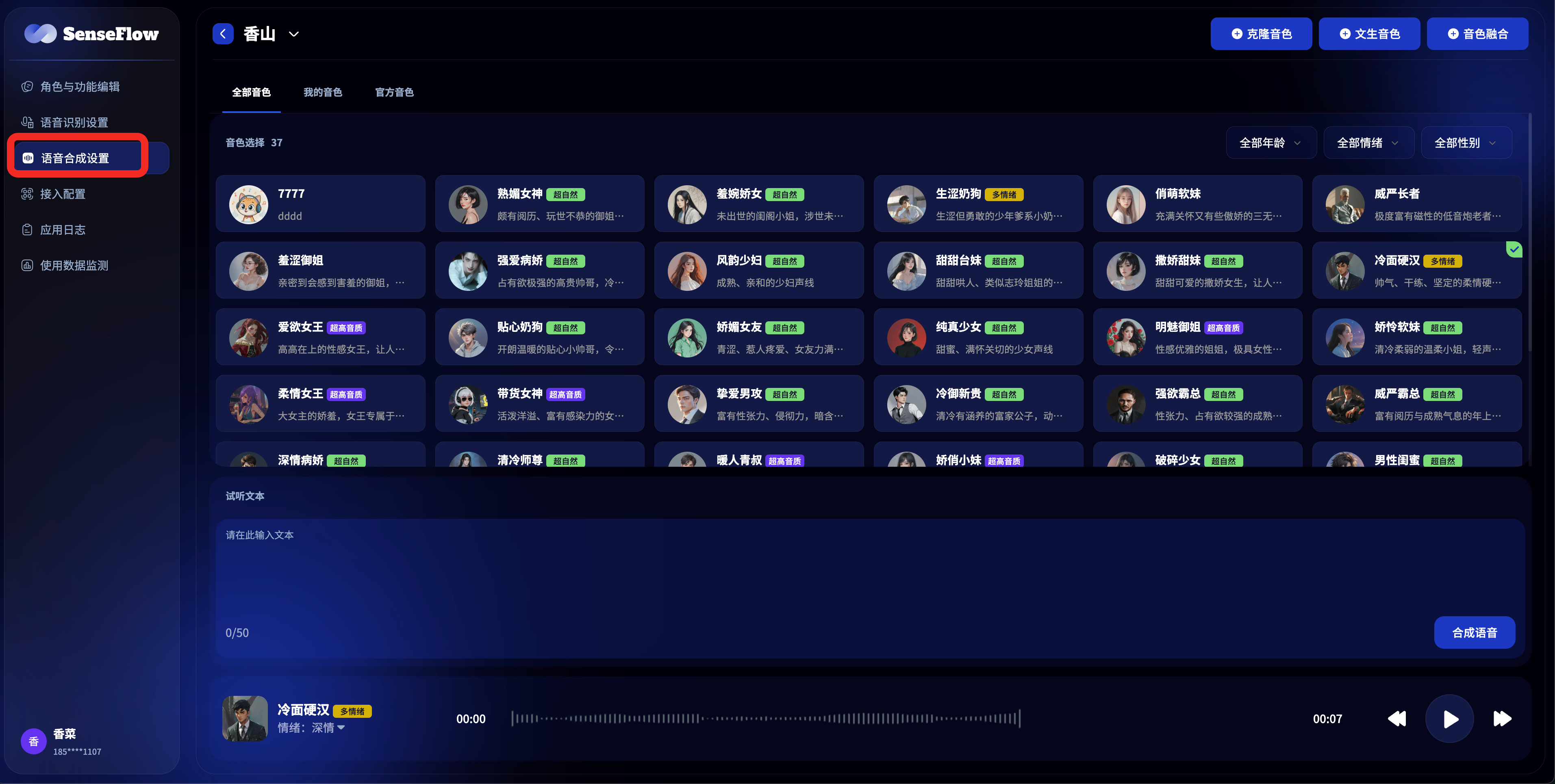
语音合成设置
音色选择
选择适合的声音类型和语言,您可以根据应用场景选择不同性别、年龄和语言的音色:
- 基础音色:提供多种预设的男声、女声音色
- 情感音色:支持不同情绪表达的音色变化
- 多语言支持:支持中文、英文等多种语言的��语音合成
- 个性化音色:支持克隆音色和自定义音色创建
语音参数调节
- 语速控制:调整语音播放的快慢程度
- 音调调节:设置语音的高低音调
- 音量控制:调整语音输出的音量大小
- 停顿设置:配置语音中的自然停顿
实时预览
您可以在调试区域实时预览语音合成的效果:
- 试听功能:即时听到配置后的语音效果
- 文本测试:输入测试文本验证语音质量
- 效果对比:对比不同配置下的语音效果
语音识别配置
在语音识别配置中,您可以进行以下设置:
识别精度设置
- 标准模式:适用于一般场景,平衡识别速度和准确性
- 高精度模式:适用于对准确性要求较高的场景
- 实时模式:适用于需要实时响应的交互场景
语言和方言支持
- 多语言识别:支持中文、英文等多种语言识别
- 方言支持:支持不同地区的方言识别
- 语言自动检测:自动识别用户使用的语言
环境适应性
- 噪音过滤:自动过滤背景噪音,提高识别准确性
- 音量自适应:自动调整识别灵敏度适应不同音量
- 多人识别:支持多人语音的分离识别
高级语音功能
情感化语音
- 情绪识别:识别用户语音中的情感状态
- 情绪响应:根据识别到的情绪调整回复语音的情感色彩
- 情感匹配:确保语音回复与用户情绪状态相匹配
语音克隆
- 个人音色克隆:基于样本音频创建个性化音色
- 快速克隆:通过少量样本快��速生成专属音色
- 音色融合:将多个音色特征融合创建新音色
多模态交互
- 语音+文本:同时支持语音和文本输入
- 语音+图像:结合语音指令和图像信息进行交互
- 语音+手势:支持语音与手势的组合交互
配置最佳实践
应用场景优化
- 客服场景:选择亲和、专业的音色,配置中等语速
- 教育场景:选择清晰、有耐心的音色,适中的语速和停顿
- 娱乐场景:选择活泼、有趣的音色,可以稍快的语速
- 办公场景:选择正式、简洁的音色,正常语速
性能优化建议
- 网络环境:确保稳定的网络连接以保证语音服务质量
- 设备兼容:测试不同设备上的语音功能表现
- 延迟控制:优化配置以减少语音处理延迟
- 资源管理:合理分配计算资源,平衡功能和性能
用户体验优化
- 个性化设置:提供用户自定义语音参数的选项
- 反馈机制:收集用户对语音质量的反馈
- 容错处理:设置语音识别失败时的备选方案
- 多样化选择:提供多种音色和语音风格供用户选择
注意事项
隐私保护
- 数据安全:确保语音数据传输和存储的安全性
- 用户授权:在使用语音功能前获得用户明确授权
- 数据最小化:只收集和处理必要的语音数据
- 透明度:向用户说明语音数据的使用方式和目的
合规要求
- 法规遵守:遵守相关地区的语音数据处理法规
- 用户权利:保障用户对语音数据的知情权和控制权
- 数据留存:按照法规要求管理语音数据的留存时间
- 第三方服务:确保使用的第三方语音服务符合合规要求
技�术限制
- 网络依赖:语音功能需要稳定的网络连接
- 设备要求:确保用户设备支持音频输入输出功能
- 兼容性:考虑不同平台和浏览器的兼容性问题
- 性能影响:语音处理可能对系统性能产生一定影响
通过合理配置语音与识别能力,您可以为用户提供更加自然、便捷的交互体验,提升应用的整体用户满意度。
下一步:开始创建您的第一个智能应用,体验SenseFlow的强大功能!